Learn how to crawl a website and convert pages into embeddings using the Embeddings API by OpenAI tutorial. Check the details of the AI Web Crawler below!
About OpenAI API
The OpenAI API is versatile and can be used for various tasks that involve comprehending or creating natural language and code. The OpenAI API can also be used to generate and edit images or convert speech into text. We offer a range of models with different capabilities and price points, as well as the ability to fine-tune custom models.
How to build an AI to answer questions for a website
This tutorial walks through a simple example of crawling a website (in this example, the OpenAI website), turning the crawled pages into embeddings using the Embeddings API, and then creating a basic search functionality that allows a user to ask questions about the embedded information. This is intended to be a starting point for more sophisticated applications that make use of custom knowledge bases.

Some Basics
Some basic knowledge of Python and GitHub is helpful for this tutorial. Before diving in, make sure to set up an OpenAI API key and walk through the quickstart tutorial. This will give a good intuition on how to use the API to its full potential.
Python is used as the main programming language along with OpenAI, Pandas, transformers, NumPy, and other popular packages. If you run into any issues working through this tutorial, please ask a question on the OpenAI Community Forum.
To start with the code, clone the full code for this tutorial on GitHub. Alternatively, follow along and copy each section into a Jupyter notebook and run the code step by step, or just read along. A good way to avoid any issues is to set up a new virtual environment and install the required packages by running the following commands:

How to set up a web crawler?
This tutorial mainly centres around the OpenAI API. If you’d rather not, you can skip the part about creating a web crawler and download the source code directly. Otherwise, you can expand the section below to learn how to implement the scraping mechanism.
Building an embeddings index
- CSV is a common format for storing embeddings.
- You can use this format with Python by converting the raw text files (which are in the text directory) into Pandas data frames.
- Pandas is a popular open-source library that helps you work with tabular data (data stored in rows and columns).
- Blank empty lines can clutter the text files and make them harder to process. A simple function can remove those lines and tidy up the files.

Converting the text to CSV requires looping through the text files in the text directory created earlier. After opening each file, remove the extra spacing and append the modified text to a list. Then, add the text with the new lines removed to an empty Pandas data frame and write the data frame to a CSV file.
Extra spacing and new lines can clutter the text and complicate the embedding process. The code used here helps to remove some of them but you may find 3rd party libraries or other methods useful to get rid of more unnecessary characters.
Tokenization is the next step after saving the raw text into a CSV file. This process splits the input text into tokens by breaking down the sentences and words. A visual demonstration of this can be seen by checking out our Tokenizer in the docs.
A helpful rule of thumb is that one token generally corresponds to ~4 characters of text for common English text. This translates to roughly ¾ of a word (so 100 tokens ~= 75 words).
To comply with the API’s limit on the maximum number of input tokens for embeddings, dividing the text in the CSV file into multiple rows is necessary. We must first determine the length of each row to identify which ones require splitting.
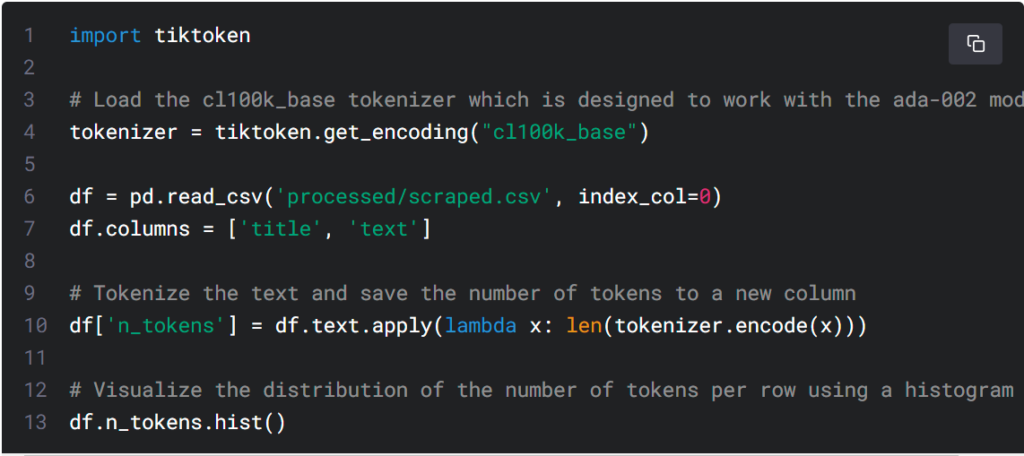
The latest embedding model can process inputs with up to 8191 input tokens. Therefore, chunking may not be necessary for most rows. However, some subpages may require splitting longer lines into smaller chunks, which will be addressed in the next code chunk.
For more information click here to view the codes
Click here to view the official page of How to Build a Web Crawler with OpenAI
Click here to learn more about Chat GPT Plugins.












